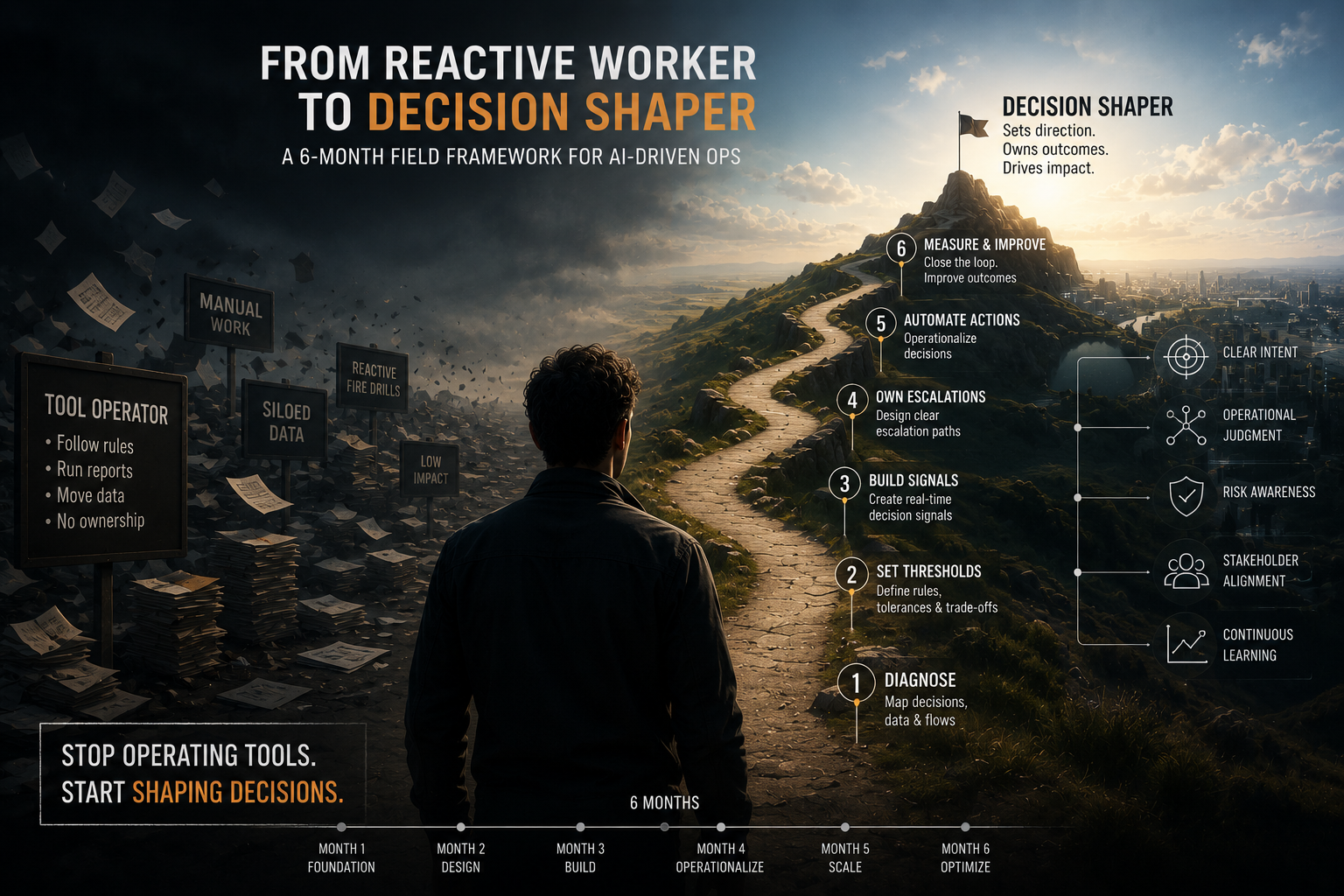
How to Become a Decision Shaper in 6 Months: A Field Framework for AI-Driven Ops
Stop operating tools. Start owning thresholds, trade-offs, and escalations.
If you have been operating tools and want to understand why that position is exposed, read AI Won’t Reward More Tools — It Rewards People Who Pick Cutoffs first. Then come back here for the roadmap.
Start today by picking one decision your system makes at scale. Pull the last 50 cases where an AI score or rule drove an action. Label each as right, wrong, or unclear based on outcome you care about. Write down what would have triggered a different action in real time. Do this now and you will see where you need judgment, not another tool.
Here is the six-month path to move from tool operator to decision shaper. You will build a decision contract, set guardrails, and take on-call ownership. Each step ends with a deliverable you can share with your team. Ship the deliverables and your role changes.
Month 1: Map the decision and define regret. Select one high-volume, high-cost decision like approve, route, or escalate. Document inputs, the current cutoff or rule, who executes, and what happens when it is wrong. Define regret in plain terms: what hurts more, a false block or a false pass, and by how much in business terms. Put this in a one-page decision brief and get a leader to sign it.
Month 2: Set thresholds and a risk budget. Convert regret into numeric cutoffs your system can act on. Set a risk budget you can spend in a period without executive approval, expressed as units leaders care about, like dollars, accounts, or minutes. Make the budget small enough to force choices but large enough to be useful in a live incident. Publish these numbers in your runbook and link them in chat topics and dashboards.
Month 3: Build the escalation path and timeboxes. Write a simple path: when the metric crosses X for Y minutes, you take Z action without asking; if it persists beyond T minutes, you escalate to role A; if that fails, you pull lever B. Timebox each step so no one argues during an incident. Put phone numbers, Slack channels, and calendar links in the runbook. Run a 15-minute drill with the team to test the path.
Month 4: Create levers you can pull fast. Add slowdowns, blocks, approvals required, or extra verification that you can toggle in minutes. Document the side effects of each lever on customer experience, cost, and compliance. Tie each lever to a metric and a threshold from your risk budget. Verify you can flip each lever from your on-call laptop.
Month 5: Install feedback loops and decision logging. Capture every override and lever change with who, why, and what threshold triggered it. Review weekly for regret, not blame: what signal would have avoided the override, and what cutoff would have made it automatic. Turn repeated overrides into new thresholds or policies. Publish a short changelog to make learning visible.
Month 6: Hand routine choices to the system and keep the judgment. Move the median case to automation under your thresholds. Keep human review for cases that break your risk budget, hit unusual patterns, or cross your timeboxes. Your value is now in shaping cutoffs, picking levers, and owning the escalation. Write your successor playbook so others can operate; you keep improving the contract.
This progression mirrors the split I described in Analytics Jobs Will Split in Two — you are deliberately moving from the tool-operator side to the decision-shaper side.
Use the DRASTIC framework to hold it all together under pressure. DRASTIC is Define the decision, Risk budget, Alerts and thresholds, Stops and slowdowns, Triage and escalation, Information logging, and Cadence of reviews. Print DRASTIC on your runbook cover and use it as a checklist in every incident. The team will copy what you model.
Apply it when the room is hot. On a Saturday night at a marketplace, card testing hit checkout and authorization traffic spiked. The fraud model started passing borderline orders because approval rates fell; support chat lit up as banks flagged transactions. We opened the runbook, read the threshold aloud, and pulled the pre-approved hold lever for mid-risk scores. Finance got a heads-up with the risk budget we were spending and the timebox on the hold.
Run the first 15 minutes like this. Minute 0 to 5: confirm the metric breach against the threshold and start a public incident channel. Minute 5 to 10: pull the first lever tied to that threshold and post the expected side effect and review time. Minute 10 to 15: assign one person to watch the regret metric and another to talk to upstream partners or vendors. This pace prevents analysis freeze and turns chatter into owned actions.
Face the uncomfortable trade-off: to stop loss fast, you will hit some good customers. During the marketplace incident, we chose temporary friction on suspicious patterns instead of a full block. That kept new revenue flowing while we cut the attack surface. If you are not willing to take near-term customer pain within a defined budget, you are not owning the decision.
Strong teams pre-decide their pain. They write down what they will sacrifice first, for how long, and who can lift the restriction, and they practice it. They keep lever changes under source control, not tribal memory. When the alarm goes off, they execute the contract; after, they adjust thresholds based on logged regret.
Average teams default to tools and vibes. They scroll dashboards, ask for more data, and wait for a senior person to say go. They tweak prompts or add a rule mid-incident without a rollback plan. Their postmortems name systems, not owners, so every incident starts from scratch.
Make this stick by taking visible ownership. Volunteer for the next on-call and announce the risk budget and thresholds before your shift. Tell the team what you will pull at which numbers and for how long. After the shift, share a one-page log of what you changed and why; invite edits to the runbook.
If you manage people, tie growth to decision ownership. Promote the analysts who write thresholds, pull levers, and escalate on time. Rotate operators through on-call so everyone learns the pain of vague policies. Reward teams that retire dashboards that do not change decisions.
Do not wait for your title to change. Pick one decision, write the contract, and own the next incident. In six months you will not be the person clicking buttons; you will be the person shaping outcomes.
If you want a structured way to evaluate your current exposure, take the AI Job Risk Assessment. It shows you which parts of your role are exposed and what to build next.
Choose a side: six months from now, will you publish thresholds and carry the pager, or will you keep polishing tools while others make the calls?